
Dalam dunia biostatistika, siapa yang tidak mengetahui tentang regresi linier? Tentu, semua orang mengetahuinya. Regresi linier merupakan salah satu konsep penting untuk analisis data biologi. Saat melakukan penelitian, kita sering kali ingin mengetahui hubungan antara dua variabel (misalnya hubungan berat badan dengan tekanan darah). Regresi linier memungkinkan kita untuk mengukur sejauh mana variabel satu dapat memengaruhi variabel yang lain. Juga, kita dapat melakukan memprediksi nilai variabel dependen menggunakan nilai variabel independen [1]. Dengan memelajari regresi linier, kalian dapat dengan mudah menganalisis data biologi, menemukan pola, dan mengungkap hubungan antara variabel-variabel.
Dalam artikel ini, saya akan menjelaskan tentang konsep dasar regresi linier dan cara mengimplementasikannya menggunakan Python.
Konsep regresi linier sederhana
Bayangkan kita memiliki sebuah data yang berisi jumlah ruangan dan harga rumah. Kita diminta untuk memprediksi harga rumah dari data jumlah ruangan tersebut. Mari kita selesaikan permasalahan ini menggunakan regression thinking.
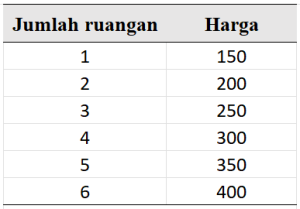
Berdasarkan informasi dari data tersebut, berapakah harga rumah yang memiliki 7 ruangan? Benar, jawabannya adalah $450. Kalian mungkin menyadari bahwa semakin banyak jumlah ruangan, harga rumah semakin besar. Dari pola tersebut, kita dapat menyimpulkannya setiap kenaikan 1 ruangan, harga rumah bertambah +50. Kita bisa membayangkan harga tersebut diperoleh dari harga dasar ($100) dan harga tambahan setiap ruangan (+50). Oleh karena itu, kita dapat menyederhanakannya dalam sebuah formula:
harga = 100 + 50(jumlah ruangan)
Apa yang kita miliki disini adalah formula untuk memprediksi harga rumah berdasarkan harga dasar dan jumlah ruangan. Dengan menggunakan formula tersebut, kita dapat memprediksi kemungkinan harga rumah yang memiliki 7 ruangan adalah $450.
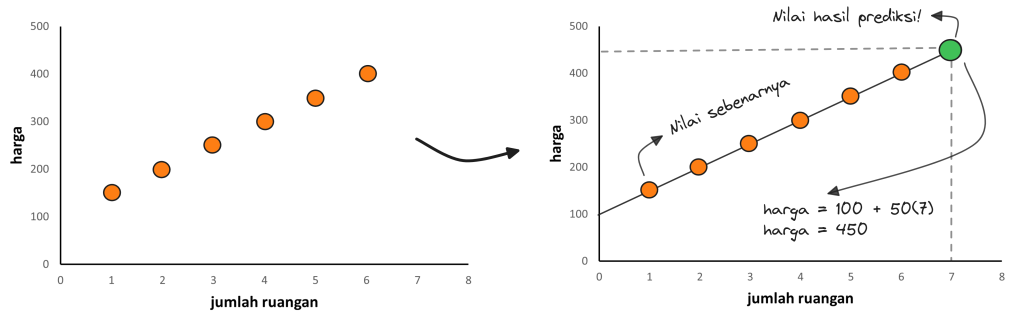
Formula yang kita dapatkan tersebut sebenarnya sama seperti formula pada regresi linier sederhana. Pada regresi linier sederhana fomulanya sebagai berikut:

Ya, kita sebenarnya sudah pernah memelajari formula regresi linier sederhana saat masih di sekolah menengah. Saat itu, kita mungkin hanya menggunakannya untuk mencari gradien garis lurus. Makna setiap notasi pada formula tersebut sebagai berikut:
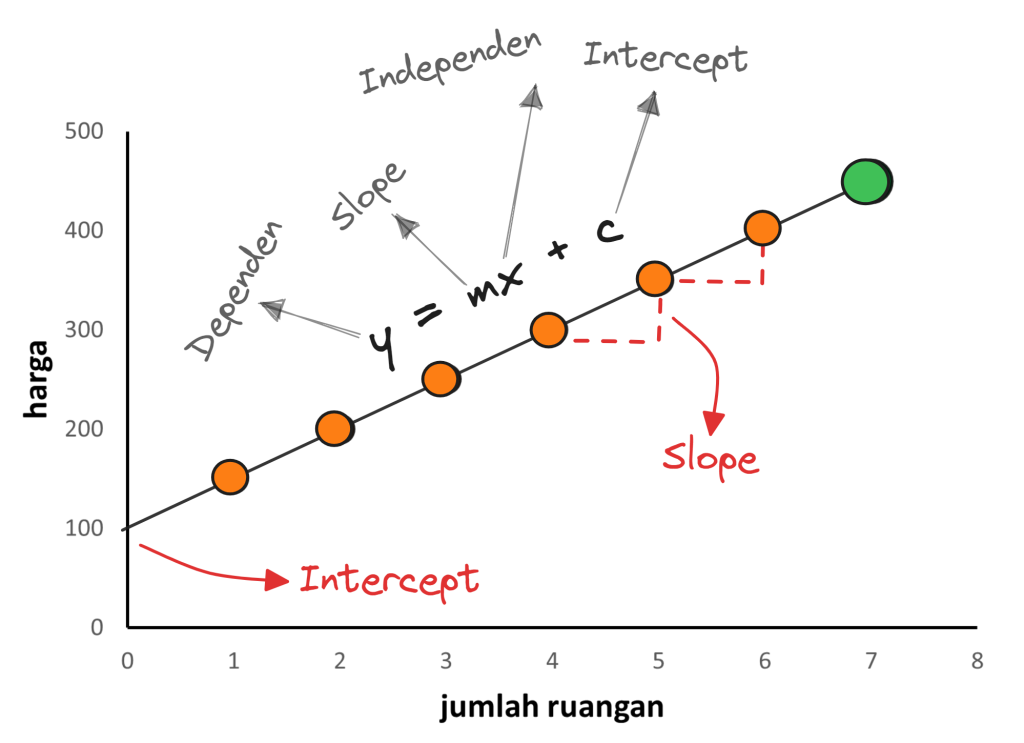
- y → variabel dependen/target yang kita coba prediksi nilainya dari variabel independen. Dalam contoh kasus di atas, ini merupakan “harga”.
- x → variabel independen yang kita gunakan untuk membuat prediksi. Dalam contoh kasus di atas, ini merupakan “jumlah ruangan”.
- m → slope adalah kemiringan/gradien garis regresi yang memberi tahu kita seberapa banyak kita berharap nilai y meningkat ketika kita meningkatkan nilai x sebesar satu unit.
- c → intercept memberi tahu kita di mana garis regresi memotong sumbu y vertikal.
Memahami cara kerja regresi linier sederhana
Regresi linier bekerja dengan cara menarik garis lurus yang sedekat mungkin dengan keseluruhan titik data [2]. Titik data yang saya maksud disini adalah variabel independen dan dependen. Ketika kedua variabel tersebut memiliki hubungan secara linier, kita dapat menghasilkan garis regresi diantara titik data tersebut.

Bagaimana cara kita menentukan garis regresi? Serrano (2016) [2] menjelaskan cara kerja regresi linier sebagai berikut:
- Langkah pertama adalah menginisiasi garis lurus secara acak.
- Kemudian, memiliih titik data secara acak dan menyesuaikan garis tersebut sedekat mungkin dengan titik data.
- Mengulangi langkah kedua beberapa kali hingga kita mendapatkan garis yang sedekat mungkin dengan semua titik data.

Kemudian, bagaimana cara kita mengetahui seberapa baik garis regresi tersebut? Garis regresi yang baik memiliki kesalahan paling minimal dalam melakukan prediksi. Artinya, garis tersebut dapat memprediksi suatu nilai dengan kesalahan paling minimal.


Sebelum melakukan regresi linier sederhana menggunakan Python, kalian harus mengunduh kumpulan data yang kami gunakan terlebih dahulu di Kaggle. Kalian juga dapat mengakses kode lengkapnya pada Google Colabolatory.
Melakukan regresi linier sederhana menggunakan Python
Setelah mendapatkan gambaran tentang konsep regresi linier sederhana, kita akan melanjutkannya dengan melakukan regresi linier sederhana menggunakan Python. Ada beberapa library yang perlu kita impor terlebih dahulu yang dapat memudahkan kita saat membangun model regresi sederhana.

Selanjutnya, kita dapat memuat dan membaca kumpulan data tersebut menggunakan Pandas.

Kumpulan data tersebut memiliki dua kolom, “Hours” dan “Scores”. Kolom “Hours” akan menjadi variabel independen, sedangkan kolom “Scores” akan menjadi variabel dependen yang kita coba prediksi nilainya. Selain itu, dataset hanya terdiri dari 25 baris dan tidak terdapat missing value. Kita juga perlu memisahkan kumpulan data tersebut menjadi data pelatihan dan data uji. Data pelatihan digunakan untuk membangun model regresi sederhana, sedangkan data uji digunakan untuk mengevaluasi seberapa baik model kita. Sekarang saatnya membangun model regresi!

Untuk membangun dan melatih model regresi sederhana, kita dapat menggunakan Scikit-learn. Untuk melihat kecocokan model regresi dengan kumpulan data, kita dapat memvisualisasikannya menggunakan Matplotlib.

Model regresi sederhana tersebut tampaknya cukup bagus dalam menggambar garis linier antara sekumpulan titik data. Seperti yang telah kita bahas di atas, rumus regresi linier adalah sebagai berikut:
Untuk mengetahui nilai persamaan regresi yang dihasilkan model, kita harus menampilkan nilai intersep dan slope.

Dari nilai intercept dan slope dapat diketahui bahwa persamaan regresi yang dihasilkan oleh model adalah y = 9.82609393X + 1.91863322.
Kemudian, kita juga harus mengevaluasi seberapa baik model regresi tersebut. Salah satu metrik standar untuk mengevaluasi model regresi linier adalah R-squared (R²) [3].

Nilai R² dari 0.9230325919412203menunjukkan bahwa model regresi linier sederhana yang kita buat sudah cukup baik. Nilai R² berada pada rentang 0 hingga 1, akurasi model regresi semakin baik jika nilai R² mendekati 1 [4].
Kesimpulan
Regresi linier sederhana merupakan konsep biostatistika yang paling mendasar dalam analisa data biologi. Ini bekerja dengan menginisiasi garis lurus secara acak, menyesuaikan garis ke setiap titik data, dan mendapatkan garis yang sedekat mungkin dengan keseluruhan titik data. Selain digunakan untuk menentukan korelasi antar data, regresi linier sederhana juga dapat digunakan untuk melakukan prediksi. Metrik yang biasa digunakan untuk mengevaluasi seberapa baik model regresi linier adalah R-squared (R²) .
Daftar Pustaka
[1] Hackeling, G. (2017). Mastering Machine Learning with Scikit-Learn. Packt Publishing.
[2] Serrano, L. (2021). Grokking Machine Learning. Manning Publications.
[3] Chicco, D., Warrens, M., & Jurman, G. (2021). The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Computer Science.
[4] Al-Mosawe, A., Kalfat, R., & Al-Mahaidi, R. (2017). Strength of Cfrp-steel double strap joints under impact loads using genetic programming. Composite Structures.
Jika masih ada banyak hal yang tidak dimengerti silahkan ajukan pertanyaan Kalian pada kolom komentar 🙂